

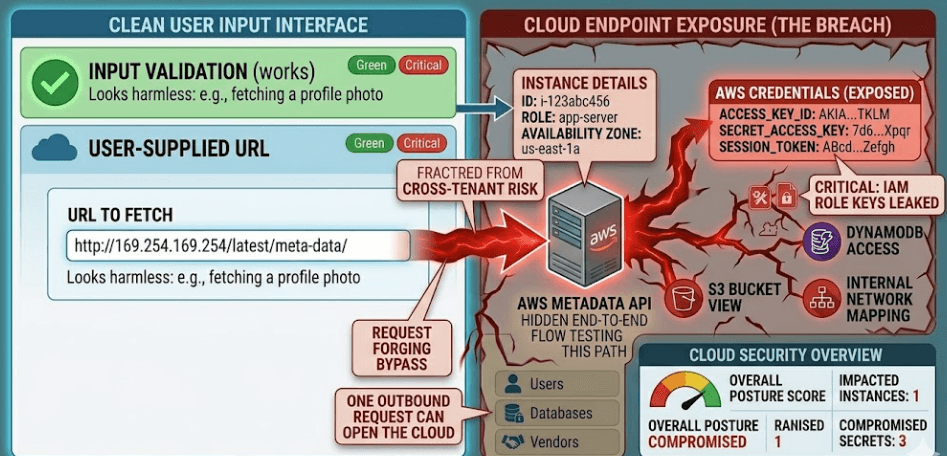
A cloud app can look perfectly normal and still be one bad URL away from losing its credentials. That is what makes server-side request forgery so dangerous in 2026. The app thinks it is helping a user fetch a resource, but the attacker is really using your server as a bridge into places that should never be public.
The real problem is trust in outbound requests
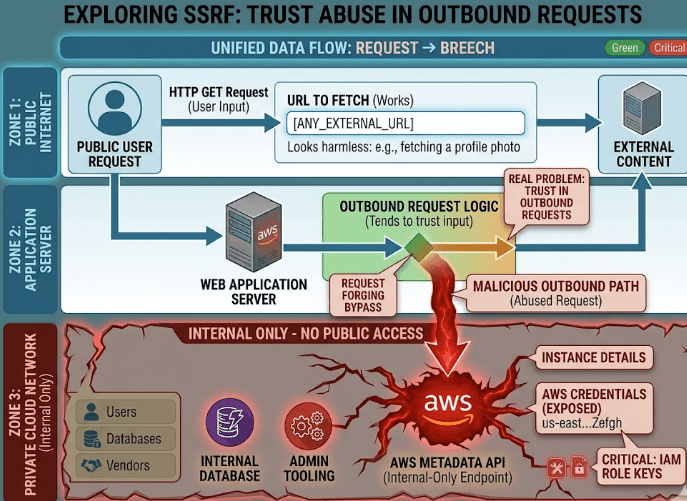
Most teams think about security at the edge. They protect login pages, lock down APIs, and scan for common web bugs. SSRF slips through because it lives somewhere less obvious. It abuses a server’s ability to make requests on behalf of a user, which sounds harmless until that request is aimed at an internal service, a private endpoint, or a cloud metadata API.
The systemic issue is that many applications treat user-supplied URLs as routine inputs. A preview feature, a webhook tester, an image fetcher, or an import tool accepts a URL and sends a request. That is fine when the target is a public resource. It becomes a problem when the server can reach private network ranges, loopback addresses, or the metadata service that cloud platforms expose to instances.
In cloud environments, the metadata API is especially valuable to attackers because it often contains credentials, role information, instance details, and other sensitive configuration data. If an app can be tricked into requesting that endpoint, the attacker may gain the same trust the server already has. That is why SSRF is not just a web bug. It is a trust escalation from user input to infrastructure access.
What it looks like in real cloud apps
A common example is a URL fetch feature. A product lets users paste a link to preview a page, validate a webhook, or pull a document. If the server does not strictly control where that request goes, an attacker can replace the public URL with an internal one. The server makes the request, receives the response, and may pass the data back to the attacker.
Another example is when an application runs in AWS, Azure, or GCP with broad instance permissions. Even if the metadata service is not exposed directly to the internet, the application itself can reach it from inside the environment. That means an SSRF flaw can become a credentials issue, then a permissions issue, then a wider cloud compromise. The attack does not need to be loud. It only needs the app to make one request it should never have made.
This is why the bug is so persistent. Developers build useful networked features, but the security model does not always follow. The app is trusted to connect outward, and that trust becomes the attack path.
Why standard defenses miss the edge
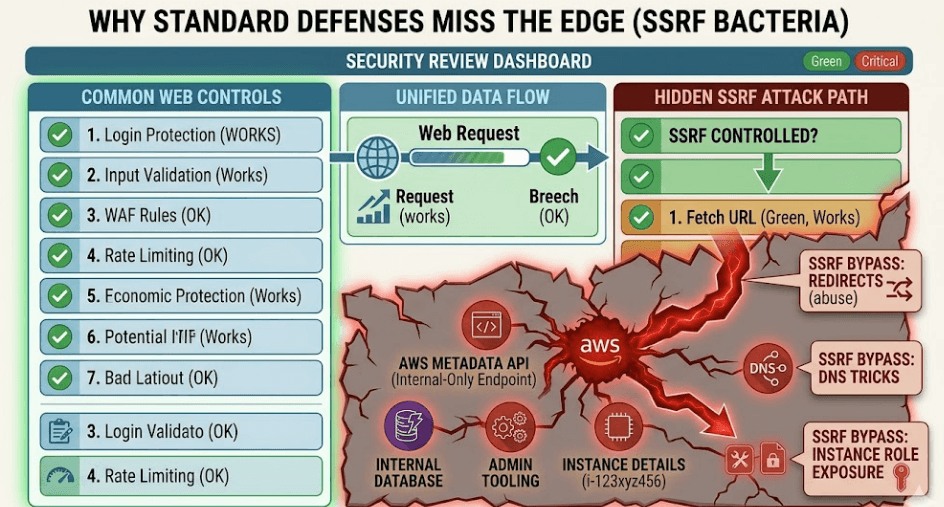
Traditional web security checks do not always catch SSRF because the request often looks legitimate. The server is allowed to make outbound calls. The URL may be well formed. The response may even be expected by the feature. What breaks is the destination, not the syntax.
Another gap is that many reviews focus on inbound traffic and forget outbound behavior. Teams inspect what comes into the app, but SSRF is about what the app can reach after it gets the input. That means the dangerous part is not the request format alone. It is the server’s network position, its IAM permissions, its metadata access, and whether redirects or DNS tricks can push the request somewhere unexpected.
Cloud defaults can make this worse. If instance roles are broad, the damage from metadata exposure grows quickly. If metadata protection is weak, the attack becomes easier. If private network segmentation is loose, the server may be able to reach more internal targets than the team realizes. The flaw is often not one mistake. It is a chain of assumptions that line up in the attacker’s favor.
What actually helps
The first step is to stop treating outbound requests as low risk. Every user-supplied URL should be checked against a strict allowlist, and the app should reject unexpected schemes, hosts, and redirects. The server should never be able to fetch arbitrary destinations just because a user asked it to.
The second step is to reduce what the cloud instance can do if SSRF succeeds. Instance roles should follow least privilege, and metadata protections should be enabled wherever possible. Network controls should block access to internal addresses that the app does not need. Even if an attacker reaches the request path, the blast radius should stay small.
The third step is to test real application flows, not just isolated endpoints. SSRF often hides in features that look useful and harmless. That is why teams benefit from automation that can probe those workflows and surface the risky paths early. Tools like Axeploit are useful here because they help find SSRF-adjacent issues such as broken access control, auth bypass, and business logic flaws before they combine into a larger cloud incident.
Bottom Line
In cloud environments, SSRF is rarely just a single bug. It is a path from user input to internal trust, then from internal trust to credentials, and from credentials to infrastructure control. The teams that stay safe are the ones that treat outbound requests as part of the attack surface, not a background feature. If you want to test that path before production, you can run an automated scan with Axeploit.



