

Broken access control is still the easiest way for a modern product to betray its own users. The login can be strong, the UI can look polished, and the app can still hand the wrong person the wrong data with one tiny request change. That is why this issue stays at the top of the OWASP list in 2026. It does not require exotic techniques, only a system that trusts too much.
Authorization fails where teams assume trust
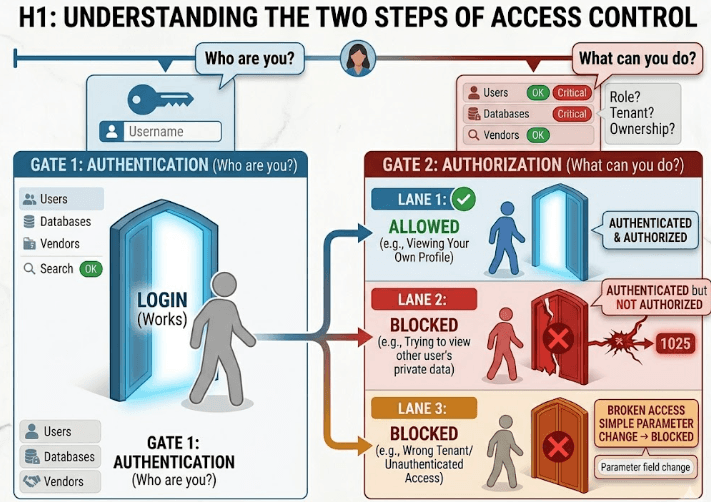
The reason broken access control keeps winning is simple. Teams spend a lot of time protecting entry and very little time proving that people can only do what they are supposed to do after entry. Authentication answers one question, which is who are you. Authorization answers the harder one, which is what are you allowed to touch. Many products blur those two together and assume that a logged-in user is a safe user. That assumption is where the trouble starts.
In practice, broken access control often comes from convenience. A developer builds a feature fast and checks whether the user is signed in, then forgets to verify whether they own the object, belong to the tenant, or have the right role. The code works. The feature ships. The bug stays hidden until someone changes an ID in the request and suddenly sees data they should never see.
The deeper problem is that access control is not one check. It is a policy that has to survive every layer of the product. APIs, admin panels, background jobs, file downloads, exports, and support tools all need the same discipline. If one path forgets the rule, the whole system becomes weaker. That is why this vulnerability stays so common. It is not because teams do not care. It is because access control is easy to get mostly right and hard to get everywhere right.
What it looks like in real products
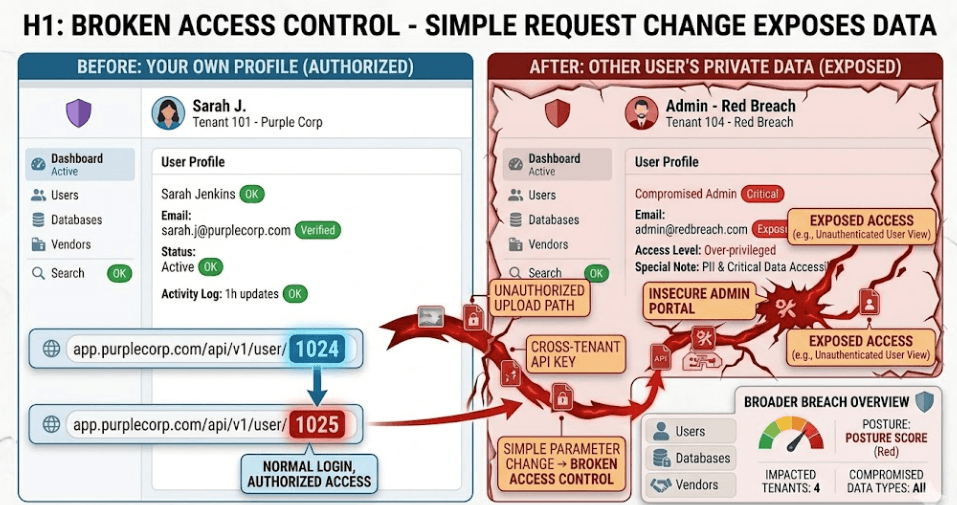
A classic example is IDOR, which means a user can reach another user’s data by changing a resource identifier. A customer support app might let a user view ticket 1024, then also let them view ticket 1025 by editing the number in the URL. The page looks normal. The authorization layer is missing. That is enough for a breach.
Another common example is role confusion. A regular employee can access an admin endpoint because the frontend hides the button but the backend never checks the role properly. A billing portal might let a user update payment settings for another account, or a SaaS dashboard might expose one tenant’s invoices to another tenant because tenant ID was not enforced in the query. These issues are small in code and massive in impact.
APIs make this even more dangerous. In a modern stack, the front end may be clean while the real risk lives in JSON requests, mobile app endpoints, and internal admin routes. A malicious user does not need to break encryption or crash the server. They only need to ask for something they should not be allowed to see and notice that the server says yes.
Why this flaw survives good engineering
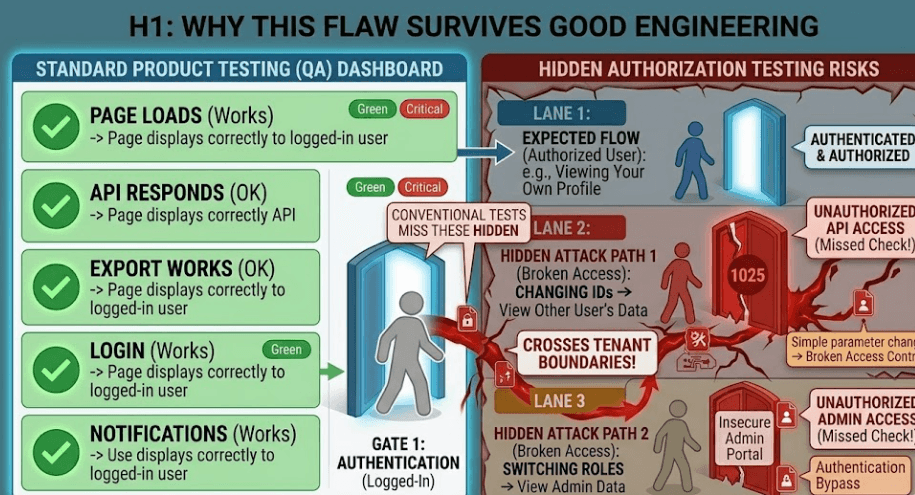
Broken access control survives because many teams test features, not boundaries. QA verifies that a profile page loads, a file downloads, or a report exports. That is useful, but it is not the same as verifying that only the right person can do it. A system can behave perfectly in the happy path and still be wide open to the wrong user.
It also survives because authorization logic often gets spread across too many places. Some checks live in middleware, some live in controllers, some live in the database, and some are implied by the UI. When the logic is fragmented like that, one missed branch can undo the rest. New features, new engineers, and rushed fixes make the problem worse because each change adds another opportunity to forget the policy.
The final reason is that broken access control does not always look scary during development. It often appears as a harmless shortcut or a temporary exception. That temporary exception becomes permanent. Then support, admin, reporting, and integrations all inherit the same weak pattern. By the time it shows up in production, the bug is no longer one endpoint. It is part of the product’s architecture.
What teams should test first
The most important test is simple. Change the object, the role, or the tenant and see what happens. If a user can access data by changing an ID, the app has an authorization problem. If a lower-privileged role can perform a higher-privileged action, the app has a role enforcement problem. If one tenant can see another tenant’s records, the product has a boundary problem.
Teams should also test the quiet places. Export jobs, password reset flows, support tools, and internal dashboards often bypass normal checks. These paths matter because they are built for speed and often receive less scrutiny than customer-facing screens. That makes them attractive targets and common sources of exposure.
The most useful mindset is to treat access control as a live behavior, not a static rule. Every time the product grows, the authorization story must grow with it. One strong check at login is not enough. The system has to prove, on every request and every workflow, that the right user is touching the right thing for the right reason.
Final thought
Broken access control stays at the top of OWASP because it is really a trust failure disguised as a technical one. The product says yes when it should say no, and that one mistake can expose customer data, damage credibility, and create a breach no one expected. The systems that stay safe are the ones that test ownership, roles, and tenant boundaries as carefully as they test features.



