

For most of software engineering history, a line of code in production implied a human who wrote it. Not necessarily a human who wrote it carefully, or well, or with security in mind. But someone made a decision, typed something, reviewed it at least once in passing, and committed it.
That assumption is quietly dissolving.
Autonomous coding agents tools configured to interpret a task, write code, run tests, resolve failures, and push commits without waiting for per-step human approval are now a standard part of how software gets built at a meaningful number of engineering teams. The productivity argument is real. An agent that can implement a feature, catch its own test failures, and retry independently is genuinely useful. Hours of developer time compress into minutes.
The security argument has not kept pace.
When a developer writes code, the act of writing is itself a moment of engagement. They are thinking about the logic. When an agent writes code, the commit arrives. The developer sees a summary, a diff, a green CI badge. They approve or they move on. What they do not do, in most cases, is read the code with the adversarial attention that finding security vulnerabilities requires.
This is not a future risk. It is a present one. And the teams most exposed to it are the ones who adopted autonomous coding the fastest, which tends to be the teams shipping the most aggressively.
What Autonomous Agents Actually Do
The category has expanded significantly in the past two years, so it is worth being specific about what is meant by autonomous coding agent in the context of this discussion.
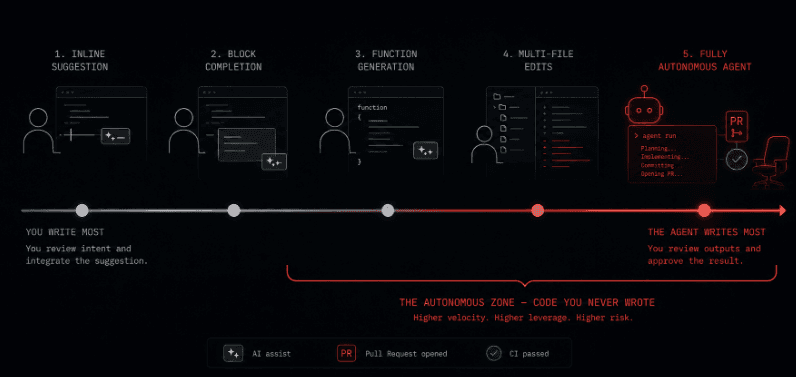
At one end of the spectrum are inline suggestion tools. A developer types, the tool suggests the next line or block, the developer accepts or rejects. The human is in the loop for every decision. The security implications of this mode are real but bounded the developer is still the author in any meaningful sense.
At the other end are fully autonomous agents. A task is described in natural language. The agent reads the codebase, creates a plan, writes code across multiple files, runs tests, observes failures, modifies the implementation, runs tests again, and opens a pull request when the suite passes. The developer's first meaningful look at the work is the pull request description.
The security gap lives in the space between those two modes, and it widens as teams push agents further toward autonomy. The more the agent does independently, the more code reaches review in a state where the reviewer is assessing something they did not participate in creating, under the cognitive pressure of a diff that is already written and tested and waiting for approval.
The Three Patterns That Create Security Gaps
Autonomous agents introduce security vulnerabilities through patterns that are structurally different from the patterns that human developers introduce. Understanding the distinction matters because the compensating controls need to be different too.
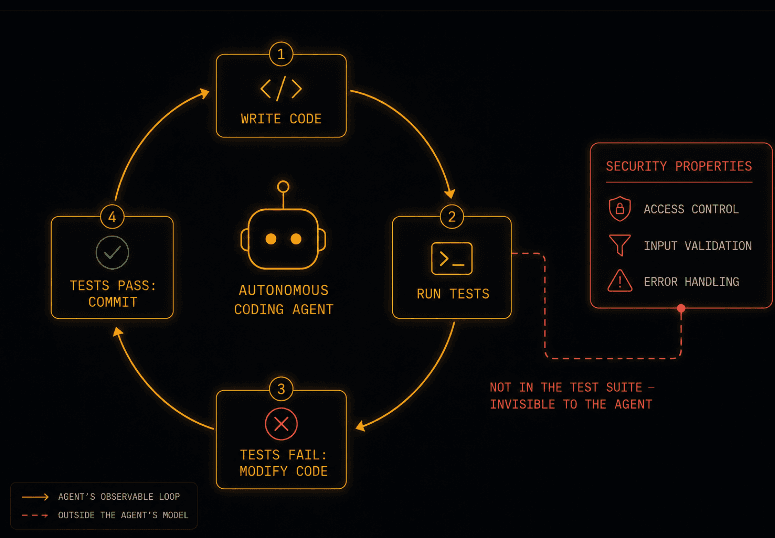
Pattern one: The agent optimizes for test passage, not for security.
When an autonomous agent encounters a failing test, it modifies code until the test passes. This is exactly what it is designed to do. The security problem is that tests almost never assert security properties. A test verifies that a user can retrieve their profile. It does not verify that a user cannot retrieve a different user's profile. A test confirms that file upload returns a 200. It does not confirm that the uploaded file is actually validated by content type before being stored.
The agent learns what "working" means from the test suite. If the test suite does not encode security expectations, the agent has no signal that security properties matter. It will produce code that passes every test and violates every access control boundary, and it will do so consistently and at scale, because the behavior is the logical consequence of the optimization target.
Pattern two: The agent resolves ambiguity toward simplicity, and simplicity is often insecure.
When a task description is ambiguous and most task descriptions are autonomous agents resolve that ambiguity by choosing the implementation that is most straightforward given the patterns available in the codebase. If the codebase has existing patterns for fetching resources by ID without checking ownership, the agent will follow that pattern. If there is an existing helper that logs errors with full stack traces, the agent will use it in new endpoints.
The agent is not being negligent. It is being consistent. It is extending the patterns of the existing codebase, including the insecure ones. In a codebase that already has authorization debt, an autonomous agent amplifies that debt systematically as it builds new features.
This is the inheritance problem at scale. Human developers occasionally catch an existing pattern and question whether it should be followed. Agents do not. They reproduce what is there.
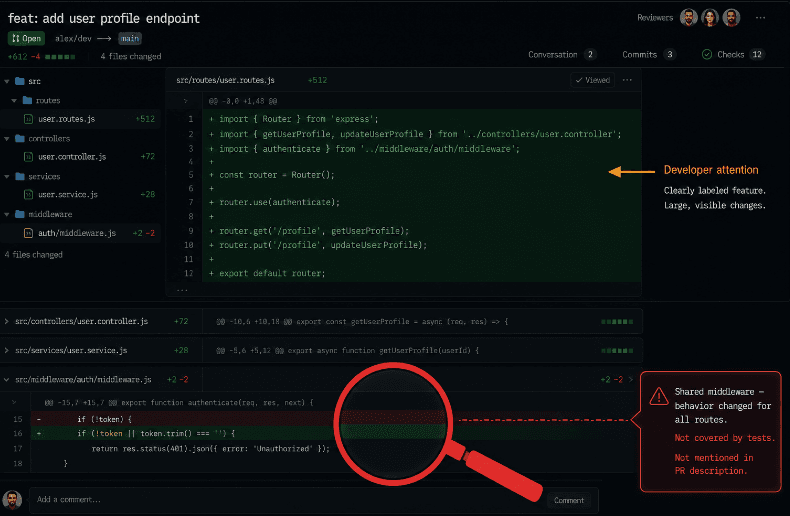
Pattern three: The agent touches files the task description never mentioned.
Autonomous agents navigate codebases to understand context. To implement a new feature, an agent might read configuration files, middleware, routing logic, and shared utilities. In the process of understanding the codebase, it sometimes modifies things adjacent to the task refactoring a helper function used elsewhere, adjusting a shared configuration value, updating an import that affects multiple modules.
These side-effect changes are exactly the changes most likely to be missed in review. The pull request description mentions the feature. The reviewer's attention is on the feature. The change to the shared authentication middleware is three files down in the diff, looks like a minor cleanup, and passes all existing tests because the tests do not cover the scenario where the middleware now behaves differently.
The Review Problem Is Architectural, Not Behavioral
The instinctive response to concerns about autonomous agent code is "engineers should review it more carefully." This is correct in principle and structurally limited in practice, for reasons that are worth spelling out precisely.
A developer reviewing a pull request created by an autonomous agent is in a different cognitive position than a developer reviewing a pull request from a colleague. When reviewing a colleague's work, the reviewer has usually had some context about what was being built, has probably had a conversation about approach, and knows roughly what to expect when the diff opens. The review is calibrated.
When reviewing an agent's pull request, the reviewer's first real exposure to the implementation is the diff itself. They are simultaneously understanding what was built and assessing whether it was built correctly. That is a heavier cognitive task, and it is performed under the same time pressure as any other code review.
More fundamentally: reading code for correctness and reading code for security exploitability are different activities requiring different mindsets. Developers who are excellent at the former are not automatically excellent at the latter. Security review requires actively imagining failure scenarios, asking what happens when the code is exercised by someone with malicious intent, looking for what is absent rather than what is present. Most code reviews do not operate in this mode, and adding "autonomous agent" to the development process does not change that.
What the agent has changed is the rate at which unreviewed surface area accumulates. If an agent can produce a feature implementation in ten minutes, and a developer spends five minutes reviewing the pull request, then the ratio of code created to code carefully examined has shifted significantly in favor of creation. That is a compounding security debt.
What Gets Missed in Practice
The vulnerability classes that autonomous agents most consistently introduce are not exotic. They are the same patterns that have appeared in security assessments for years, now arriving through a new production mechanism.
Broken object level authorization. Features that retrieve, update, or delete resources based on an ID parameter, without verifying that the authenticated user has permission to act on that specific object. The agent implemented what the task description asked for. The task description said "implement the invoice retrieval endpoint." It did not say "verify that the invoice belongs to the requesting user." So the agent did not.
Verbose error handling that exposes internal structure. Agents inherit logging and error handling patterns from the codebase. If existing error handlers return stack traces to clients, new endpoints will too. If existing error messages distinguish between "user not found" and "wrong password," new authentication logic will follow the same pattern. The agent extended the codebase's conventions consistently. The codebase's conventions were insecure.
Dependency additions that introduce known vulnerabilities. Autonomous agents sometimes install packages to solve problems they encounter during implementation. A task that requires date parsing might lead an agent to install a date library. A task requiring HTTP requests might add a new HTTP client. Those packages may have known vulnerabilities in the versions the agent installs, and they are easy to miss in a diff review where the focus is on the feature code.
Configuration changes with broad scope. Agents that modify configuration files CORS settings, content security policy headers, authentication middleware configuration in service of making a test pass can introduce changes that affect the entire application. A CORS policy loosened to make a test work is a CORS policy loosened for every consumer of that API.
The CI/CD Pipeline Does Not Catch This
Many teams point to their CI/CD pipeline as the safety net under autonomous agent workflows. Tests run automatically. Linting catches style violations. Dependency scanning might flag known CVEs. The pipeline is the guardrail.
The pipeline catches what it was configured to catch. It catches functional regressions behaviors the test suite previously confirmed that a new change has broken. It catches dependency vulnerabilities that have been catalogued in the databases the scanner queries. It catches code style deviations that linting rules prohibit.
It does not catch new authorization boundaries that were not protected. It does not catch verbose error handling that reveals internal structure. It does not catch the fact that a shared middleware was silently modified. It does not catch the access control gap in the feature the agent just built, because no test ever asserted that the access control boundary should exist.
The pipeline validates that the application still does what it was previously specified to do. It does not validate that the application now does everything the security model requires of new features.
This distinction is not a limitation of specific CI/CD tools. It is a category difference. Automated functional testing answers whether the application works. Security testing answers whether the application is safe. These are different questions requiring different approaches, and the pipeline as typically configured is good at the first and absent on the second.
What Changes When Agents Are in the Loop
The arrival of autonomous coding agents in the development workflow does not change what good security looks like for an application. It changes the rate at which unverified code reaches production and the degree to which the human review process can realistically compensate.
The implication is that security verification needs to move closer to deployment to the running application rather than the source code. Runtime testing, operating on the application as it actually behaves in a deployed state, with real authentication and real workflows and real data flows, closes the gap that static review and automated functional testing leave open.
This is not a new principle. Security testing of running applications has always been part of a complete security program. What changes with autonomous agents is the urgency of that testing and the frequency with which it needs to happen. An application that ships features daily via autonomous agent has a security surface that is changing daily. A security check performed quarterly provides a very different coverage profile than one that runs continuously.
The teams that are managing this well have made one structural change: they treat every deployment as a potential introduction of new, unreviewed attack surface, and they test that surface automatically, the same way the CI pipeline tests functional behavior. Not a replacement for code review. Not instead of dependency scanning. In addition to those things, at the layer that those things cannot reach.
Closing: The Code Arrived Before Anyone Was Ready
The productivity gains from autonomous coding agents are real and they are not going away. Teams that have deployed them are shipping faster, iterating more quickly, and spending less time on implementation work that was previously absorbing engineering capacity. These are genuine improvements.
What has not kept pace is the security verification layer. When developers wrote every line, the human in the loop provided an imperfect but real signal about what the code was doing and why. When agents write code and humans review diffs, that signal is weaker, arrives later, and operates at a cognitive disadvantage relative to the volume and speed of the code arriving for review.
The code is in production now. Some of it contains authorization gaps that nobody noticed because nobody was looking for them. Some of it has verbose error handling inherited from existing patterns that nobody questioned. Some of it modified shared infrastructure in ways the pull request description did not mention.
The appropriate response is not to slow the agents down. It is to test the application they built with the same systematic attention that an attacker will eventually apply. The attacker does not care who wrote the code. They care what the running application does when they probe it.
Testing that question, at deployment, for every deployment, is the adaptation that autonomous coding demands.
Axeploit tests what autonomous agents shipped not the code they wrote, but the application they produced. Its AI agents create accounts, authenticate as real users, exercise actual workflows, and verify whether the authorization boundaries, input controls, and error handling of new features hold under adversarial pressure. It finds the gaps that appear when autonomous coding agents optimize for test passage rather than security. And it does it at the cadence that autonomous development demands: continuously, against the running application, after every deployment.



