

A breach rarely begins with a dramatic alarm. It usually begins with something small: a missed permission check, an exposed endpoint, a leaked token, or an authentication flaw that nobody caught early enough. By the time the company notices, the attacker may already have moved through systems, accessed data, and created a chain of consequences that will take days or weeks to unwind.
For founders, the hard part is that a breach is not just a security event. It is an operational crisis, a legal risk, a customer trust problem, and a leadership test all at once. The timeline below is what many leaders only understand after the fact when they are already in the middle of it.
The first hours
The first sign is usually confusion, not certainty. An engineer sees strange traffic, a customer reports unusual account activity, a support ticket sounds suspicious, or an internal alert points to behavior that does not fit normal patterns. At this stage, the team does not yet know the full scope, which is why the first hours are often the most dangerous.
Leadership has to balance urgency with caution. Shut things down too early, and the product may go dark. Wait too long, and the attacker may keep moving. The team is forced to make decisions with incomplete information, which is exactly why preparation matters so much before an incident ever happens.
This is also the moment when the cost of missed prevention becomes visible. A vulnerability that could have been caught by proactive testing turns into an active incident response problem. What was once a fixable weakness is now a live crisis.
The first day
Once the team confirms there is a real issue, the incident stops being a technical curiosity and becomes an organizational event. Credentials may need to be rotated, access may need to be disabled, logs may need to be preserved, and a containment plan has to be formed quickly. Every action has tradeoffs, and every delay increases the risk of further exposure.
This is often the point where non-technical leaders first feel the pressure. They need answers, but answers take time. They need clarity on what happened, but the team may still be collecting evidence. They need to know whether customers are affected, but that assessment may not be complete yet. The business has already changed, even if the public has not heard about it.
Founders also learn quickly that a breach creates coordination debt. Engineering, support, legal, communications, and leadership suddenly need to work from the same timeline. If the company has never rehearsed an incident, the first day can become chaotic very fast.
The first few days
By day two or three, the incident becomes more than a technical problem. The company has to decide how to communicate, what to disclose, and who needs to be notified. Depending on the data involved and the jurisdictions affected, there may be legal or regulatory obligations that start running immediately. That makes speed important, but accuracy just as important.
This is where trust damage begins to grow. Customers do not just want to know that something happened. They want to know whether their accounts were impacted, whether personal data was exposed, and whether the company had reasonable safeguards in place. If the response is slow, vague, or inconsistent, confidence erodes quickly.
Meanwhile, internal work continues. The team may be reviewing access logs, analyzing root cause, preserving evidence, and assessing whether the issue was isolated or systemic. The incident often turns out to be bigger than the first alert suggested, because the original weakness may have been a symptom of deeper gaps in testing, monitoring, or access control.
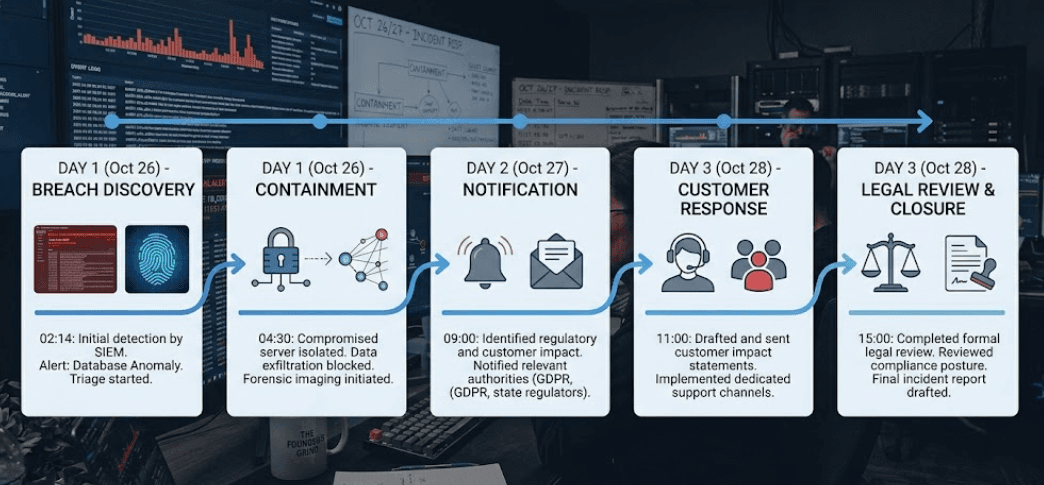
The first week
By the end of the first week, the company is no longer just responding to a breach it is managing consequences. Customers may be asking harder questions. Enterprise prospects may pause deals. Existing customers may request security assurances. Investors or board members may want updates. The business has to answer all of it while still keeping the product moving.
This is usually when leaders realize the real cost of the breach is broader than the compromised system. The company loses time, attention, and momentum. Engineers who should be building are now investigating. Founders who should be selling are now explaining. Support teams are handling increased uncertainty. A breach creates operational drag long after the initial flaw is fixed.
It is also the stage where public perception starts to settle. If the company responds with clarity and seriousness, the damage may be contained. If it responds poorly, the breach becomes part of the brand story. For a startup, that can be especially costly because trust is still being built.
Weeks after the incident
Even after the immediate crisis fades, the aftermath continues. There may be customer follow-up, contract reviews, audit questions, insurance discussions, and legal obligations that extend well beyond the original incident. The technical issue may be closed, but the organizational consequences can last much longer.
This is also when leaders start asking the uncomfortable question: could this have been prevented? In many cases, the answer is yes. A proper assessment, a proactive scan, or a validation step might have caught the issue before it became a real incident. That realization is painful because it shows the breach was not inevitable it was allowed to happen.
For startups especially, this matters because a single incident can slow fundraising, delay partnerships, complicate enterprise sales, and consume engineering time that was meant for growth. The cost is not just remediation. It is lost opportunity.
Why trust changes so fast
The most underestimated part of a breach is how quickly trust changes. Before the incident, customers assume the product is safe enough to use. After the incident, they begin looking for signs of whether the company took security seriously at all. The same product, the same team, and the same roadmap can suddenly look very different through that lens.
Trust is hard to rebuild because it depends on evidence, not intention. Saying “we fixed it” is not enough. Customers want to understand what happened, what was exposed, and what the company changed to stop it from happening again. If those answers are missing, the damage lingers.
That is why prevention is so powerful. Every vulnerability found before a breach protects more than data. It protects credibility, customer confidence, and future business opportunities. A scan that catches a weakness early can save a company from a trust event that would be far more expensive to recover from later.
Why proactive scanning matters
The story of a breach is really the story of time. The longer a weakness remains undetected, the more damage it can do. The longer the incident remains uncontained, the harder it becomes to explain. The longer the company takes to respond, the more trust it loses.
That is why proactive scanning is not a nice-to-have for startups. It is a practical way to shorten the odds of ever entering this timeline in the first place. If a tool can identify auth issues, enumeration paths, exposed secrets, or access-control weaknesses before attackers do, it buys the company time, certainty, and resilience.
For Axeploit, that is the core message: every hour prevented is an hour the company does not have to spend in crisis mode. The best breach timeline is the one that never happens because the issue was found first.
Final perspective
Founders often think of breaches as rare, dramatic events that happen to other companies. In reality, they are usually the result of ordinary weaknesses that were never fully tested. The aftermath is what turns a simple flaw into a business event one that can affect customers, revenue, reputation, and leadership confidence all at once.
The lesson is not to panic. It is to prepare. When leaders understand what happens after a breach, they make better decisions before one occurs. That is the value of proactive security work: it prevents the company from learning the hard way how expensive one missed weakness can become.



