

The idea behind rate limiting is correct. An attacker making ten thousand login attempts should be stopped. A script scraping every product in your catalog should be throttled. A credential stuffing bot cycling through a list of compromised email and password pairs should hit a wall before it gets through more than a handful of accounts.
The execution of rate limiting, in most production applications, is wrong in ways that produce the opposite of the intended outcome. The attacker gets through. The real user gets blocked. The security team sees the rate limiter firing and concludes it is working. Everyone continues.
This is not a niche failure mode. It is the modal outcome for rate limiting as typically implemented, because the most natural implementation count requests from an IP address within a time window, block when the count exceeds a threshold is built around an assumption that has not been true for a decade. Attackers do not come from a single IP address. They never have, and they certainly do not now.
What follows is a framework for building rate limiting that operates on the signals that actually differentiate attacker traffic from legitimate traffic, applied at the layers where those signals are available, without turning your rate limiter into a denial-of-service tool pointed at your own users.
Why IP-Based Rate Limiting Fails at Both Jobs
IP-based rate limiting was a reasonable design in an era when attacks came from single machines or small botnets with a limited pool of source addresses. Blocking or throttling the IP addresses doing the attacking was sufficient because the attacker's address space was limited.
That era is over. Residential proxy networks sell access to millions of IP addresses for a few dollars per gigabyte of traffic. Cloud providers assign IP addresses from ranges so large that blocking a range means blocking a significant fraction of legitimate traffic. Mobile carrier-grade NAT means that thousands of legitimate users can share a single IP address, and blocking that address means blocking all of them simultaneously.
The consequence is symmetrical failure. A threshold low enough to stop a residential proxy attack is low enough to block a busy legitimate user on a shared network or behind a NAT. A threshold high enough to not block legitimate users is high enough that an attacker with access to a residential proxy network can distribute their requests below the threshold across thousands of addresses and never trigger the limit at all.
IP-based rate limiting as a primary control is not achieving the security goal. It is achieving the user experience degradation goal while leaving the attack path unaffected.
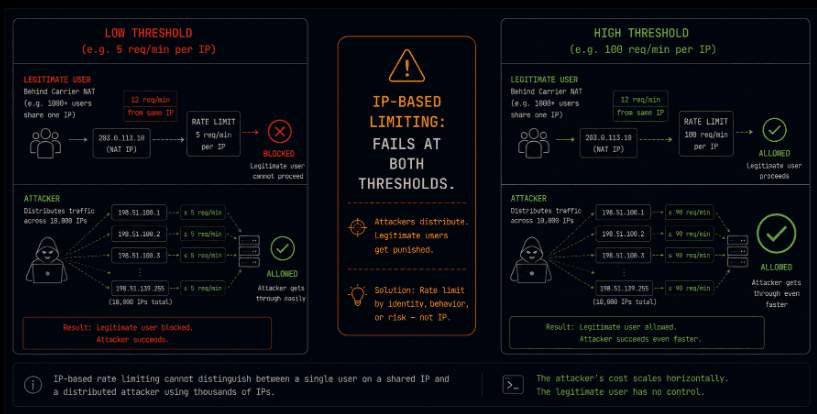
This does not mean IP-based rate limiting has no value. It still provides meaningful friction against unsophisticated attackers who cannot or have not bothered to distribute their traffic. It contributes to a layered defense. The error is treating it as the primary or sufficient control.
The Right Unit of Rate Limiting Depends on What You Are Protecting
The first design question for any rate limiting implementation is: what is the unit of counting? The answer should be derived from what the endpoint does and what the attacker's goal is not from what is easiest to implement.
For authentication endpoints, count by target account, not by source IP.
An attacker attempting to compromise a specific account will try many passwords against that account. The source IP may vary across every attempt. The target account identifier does not. Rate limiting login attempts per username or email address regardless of where the requests come from is the correct unit for credential stuffing defense. An attacker distributing requests across a thousand IP addresses still accumulates counts against the same target account.
This is structurally different from IP-based rate limiting and requires storing counts keyed to account identifiers rather than network addresses. It also requires care around account enumeration: returning a rate limit error that confirms the account exists is an enumeration leak. The rate limit response for an account-based limit should be indistinguishable from the standard authentication failure response to avoid confirming account existence.
For password reset and account recovery, count by both the requesting account and the requesting IP, separately.
A legitimate user requesting multiple password resets is unusual but possible. An attacker abusing the reset flow to exhaust reset tokens or perform enumeration is operating at a different scale. Counting resets per account catches the automated attack. Counting resets per IP catches the same attacker operating across multiple target accounts. Both limits serve different purposes and both should be present.
For API endpoints returning sensitive data, count by authenticated user.
An authenticated user retrieving their own data at high volume is unusual, but the limit should be set at a level that reflects legitimate usage patterns for that user. An authenticated user retrieving data belonging to other users is a different kind of abuse one that authorization checks should prevent, but that rate limiting on the data retrieval endpoint can provide an additional signal for. High-volume access by an authenticated user that spans many different object identifiers is a pattern worth flagging even when each individual request is authorized.
For public endpoints with no authentication, count by a combination of IP, fingerprint, and behavioral signals.
Public endpoints search, catalog browsing, public pricing are accessible without authentication by design, which means there is no account identifier to use as the counting unit. For these endpoints, the correct approach is layered: IP provides a coarse signal, browser fingerprinting provides a finer-grained signal that is harder to rotate, and behavioral patterns provide the most reliable signal of all.

Behavioral Signals That Distinguish Bots From Humans
IP addresses change. Browser fingerprints can be spoofed. Account identifiers do not help on public endpoints. The most durable signals for distinguishing automated attacker traffic from legitimate human traffic are behavioral, and they are available on any endpoint where interaction patterns differ between humans and automation.
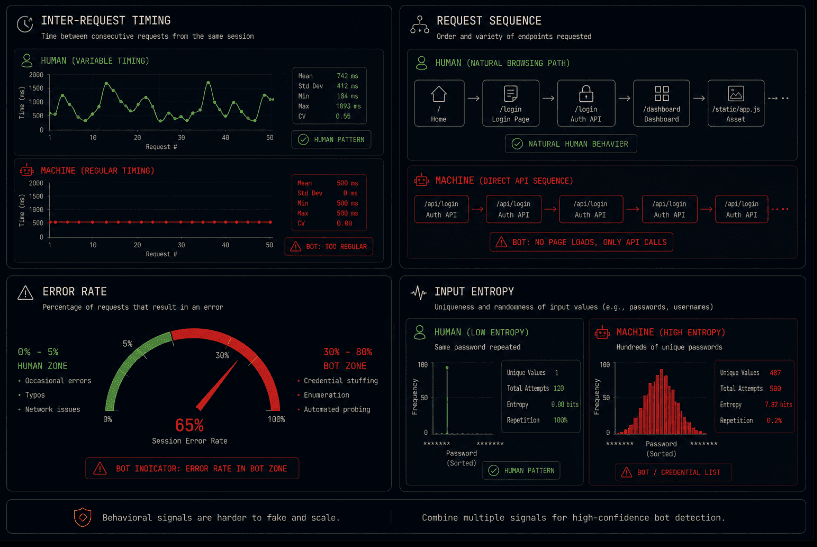
Request velocity within a session. A human browsing a product catalog takes time between page views reading, thinking, deciding. A scraper cycles through catalog pages at a consistent, machine-speed pace with no variation. The velocity of requests within a session, measured as inter-request timing, follows a distribution that is recognizably different for humans versus automation. Requests arriving at mathematically regular intervals every 500 milliseconds, every 1.2 seconds are a strong signal of automation regardless of IP address.
Request sequence patterns. Humans navigate applications in ways that reflect how interfaces are structured. They load pages, then load assets, then make API calls triggered by interaction. Automated clients skip the page loads and call API endpoints directly, or call them in sequences that match enumeration patterns rather than UI-driven navigation. A session that makes API calls without the preceding page load that would normally trigger them is unusual. A session that calls endpoints in alphabetical order, or in sequential numeric ID order, is almost certainly automated.
Error rate within a session. Legitimate users occasionally encounter errors a wrong password, a malformed form submission, a page that fails to load. Attackers cycling through credential lists encounter errors constantly, because most credentials in a stuffing list are invalid for any given target. A session with an error rate above a threshold that reflects normal user behavior is a signal worth acting on, independent of the request volume.
Field value entropy. On authentication endpoints, an attacker cycling through a credential list will produce password values with significantly different characteristics than a legitimate user who has a single password they are entering. Password attempts that cycle through a list show high variety. A legitimate user retrying their own password shows repetition. This signal requires careful handling to avoid storing sensitive values, but the entropy of the input can be tracked without storing the input itself.
The Architecture That Makes This Work
Behavioral rate limiting requires more infrastructure than IP-based rate limiting because it requires state that persists across requests and context that exceeds what a single request contains. The architectural decisions that make this practical without requiring a custom data science pipeline:
Session-level state in a fast store. Behavioral signals like inter-request timing and error rates require accumulating counts and measurements across multiple requests in a session. Redis or a similar in-memory store is the standard choice it is fast enough to add minimal latency to each request, supports atomic increment operations needed for accurate counting under concurrent load, and supports expiration for automatic cleanup of old session state.
Token bucket or sliding window over fixed window. Fixed window rate limiting count requests in this minute, reset at the top of the next minute produces a known exploit where an attacker can make double the permitted requests by timing around the reset boundary. A sliding window that counts requests in the last N seconds, or a token bucket that refills continuously, eliminates this boundary condition. The implementation is slightly more complex but the exploitation gap is closed.
Graduated response rather than binary block. A rate limiter that adds a progressive delay before responding returning responses more slowly as request frequency increases is more attacker-resistant than one that blocks at a hard threshold. A hard block is a signal to the attacker that the threshold has been crossed, prompting them to slow their rate and stay below it. Progressive delay is harder to detect and reason about, and it degrades the attacker's throughput gradually without providing a clear signal that they have triggered a control.
Separate limits for read and write operations. Write operations creating accounts, submitting payments, sending messages have lower legitimate per-user volumes than read operations, and the cost of an attacker succeeding on a write is typically higher. Separate, tighter limits for write-path endpoints allow higher read volumes for legitimate users while applying meaningful friction to the operations where abuse has the highest impact.

What to Do With Rate Limit Triggers
A rate limit that fires and blocks is the bluntest possible response. It is appropriate for some scenarios an IP sending a thousand requests per second to a login endpoint deserves to be blocked. For most scenarios, a graduated response ladder produces better outcomes for both security and user experience.
Challenge before block. A CAPTCHA or proof-of-work challenge presented when behavioral signals suggest automation is a meaningful filter. Legitimate users complete it; most automated clients cannot, or the cost of solving it at scale is prohibitive. The challenge imposes friction only on traffic that has already triggered behavioral signals, rather than on all traffic above a numeric threshold.
Step-up authentication for suspicious sessions. A session that has triggered behavioral signals on a sensitive endpoint multiple failed authentication attempts, rapid enumeration of API resources, irregular timing patterns can be required to complete a second factor before proceeding, rather than being blocked entirely. This converts a binary block into a friction event that legitimate users who happened to trigger the signals can resolve, while imposing meaningful cost on attackers.
Silent logging without blocking. For signals that are ambiguous a session with slightly elevated error rates, a timing pattern that is unusual but not definitively machine-generated logging the signal without taking action allows patterns to accumulate over time. A session that triggers multiple ambiguous signals independently is a higher-confidence indicator than any single signal alone. The cumulative pattern provides the basis for a more confident response than any individual signal would justify.
Alerting for high-confidence attack patterns. Credential stuffing attacks, scraping at scale, and enumeration attempts have signatures that are recognizable at the aggregate level even when individual requests look normal. A significant increase in authentication failures across accounts, a sudden spike in sequential API access patterns, or a large volume of new sessions with consistent behavioral signatures these are worth surfacing to a human for review rather than being handled entirely by automated blocking.
The User Experience Constraint
Rate limiting that cannot distinguish between an attacker and a legitimate power user is rate limiting that will eventually become a support ticket, a social media complaint, or a churned customer. The design constraint is not just "stop attackers" but "stop attackers without imposing meaningful friction on users who are doing things your application is designed to support."
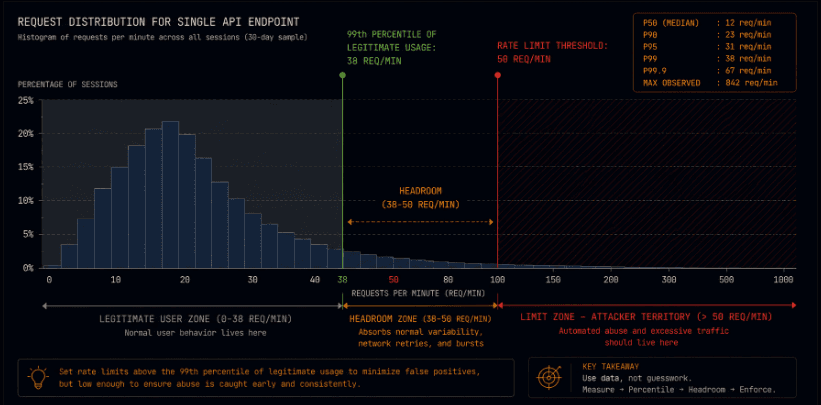
The practical implication: rate limits for authenticated users should be set based on actual usage data from real user sessions, not based on what seems conservative. If your 95th percentile legitimate user makes 40 API calls per minute on a specific endpoint, a rate limit of 20 calls per minute is a limit that fires constantly for high-engagement users and does nothing to stop an attacker who is staying below 20 calls per minute per IP address.
Build your rate limits from usage data, not from intuition. Export real session request distributions for each major endpoint. Find where legitimate usage clusters. Set limits that give meaningful headroom above the 99th percentile of legitimate usage and apply the behavioral controls for anything above that. The limits derived from data will be higher than the limits derived from instinct, and they will also be more defensible when a user complains.
Closing: The Limiter That Knows What It Is Limiting
A rate limiter that counts IP addresses and blocks at a threshold knows almost nothing about what it is limiting. It does not know whether the traffic is automated or human. It does not know whether the requests are targeting a specific account or exploring the API randomly. It does not know whether the volume reflects an attack or a legitimate high-engagement use case.
A rate limiter built on the signals in this post knows more. It knows whether the timing pattern looks like a human or a machine. It knows whether the same account is being targeted repeatedly regardless of where the requests come from. It knows whether an authenticated user's behavior within a session matches the patterns of legitimate users or the patterns of automated enumeration. It uses that knowledge to respond proportionally rather than with a blunt block that is as likely to fire on a power user as on an attacker.
The knowledge does not come for free. It requires state, it requires behavioral analysis, and it requires limits derived from real usage data rather than guesswork. It requires thinking about what each endpoint is being protected against and choosing the counting unit and behavioral signals that correspond to that specific threat.
That design work is what separates rate limiting that stops attackers from rate limiting that inconveniences users. Both implementations look the same from the outside. Only one of them is doing the job.
Axeploit tests whether your rate limiting actually stops the attacks it was designed to stop not by sending high-volume requests from a single source, but by simulating the distributed, account-targeted, behaviorally-aware attack patterns that real attackers use. It identifies the gaps between what your rate limiting assumes about attacker behavior and what attackers actually do, surfacing the paths where abuse traffic passes through while legitimate users are throttled.



