

Logging is one of the most useful habits in modern engineering, but it is also one of the easiest places to leak sensitive data. Teams add logs to debug failures, trace requests, and monitor production behavior, then gradually start capturing headers, payloads, stack traces, and session details that were never meant to leave the application boundary. What begins as useful telemetry can quietly turn into a copy of your secrets, scattered across multiple systems and retained far longer than the original request.
The danger is that logging feels harmless. It is not a public feature, users cannot directly see it, and it is usually controlled by the engineering team. That false sense of safety is exactly why log exposure is so common. Once sensitive data enters an observability stack, it can be replicated, indexed, exported, forwarded, queried, cached, and retained in ways that make cleanup much harder than people expect.
Why logs become a secret store
Logs are designed to be useful, which often means they are intentionally verbose. They capture request paths, user IDs, headers, payload fragments, exceptions, retry behavior, and upstream service failures. That verbosity is helpful during incidents, but it also increases the chance that something sensitive slips into the record. A single debug statement can accidentally expose a password reset token, an OAuth access token, or a full customer payload containing personal data.
The problem grows when logs are centralized. A secret that only existed in one runtime instance can be replicated into a shared observability platform, forwarded to multiple teams, exported into archives, and retained for months or years. Even if the original application no longer stores the data, the log pipeline may still preserve it. That turns a temporary debug artifact into a long-lived exposure surface.
Many teams also underestimate how easy it is to search logs once sensitive data is there. Observability tools are built for discovery, which means anyone with access can query by request ID, user email, endpoint, error pattern, or raw content. That makes logs extremely powerful for operations, but it also means they can become a high-value target if they contain secrets.
How secrets get in
Secrets usually enter logs through ordinary engineering work, not malicious intent. A developer adds temporary debug output to troubleshoot an issue and forgets to remove it. An application logs request headers for tracing and accidentally includes authorization values. An error handler serializes too much context and captures full request bodies. A framework or middleware layer logs a form submission, a token exchange, or an identity callback with fields that should never have been recorded.
Another common path is through third-party integrations. Payment providers, identity systems, webhook consumers, and API gateways can produce error messages or callback payloads that include sensitive metadata. If that output is stored without filtering, the observability stack becomes a downstream collector of secrets that were never intended for broad access. This is especially risky in distributed systems where multiple services log the same event from different angles.
There is also a cultural issue. Teams often view logs as engineering-only data, so they may not apply the same controls they would apply to customer data stores. But if logs contain emails, tokens, access keys, session IDs, or internal identifiers that can be linked to users, they deserve the same level of care as any other sensitive system.
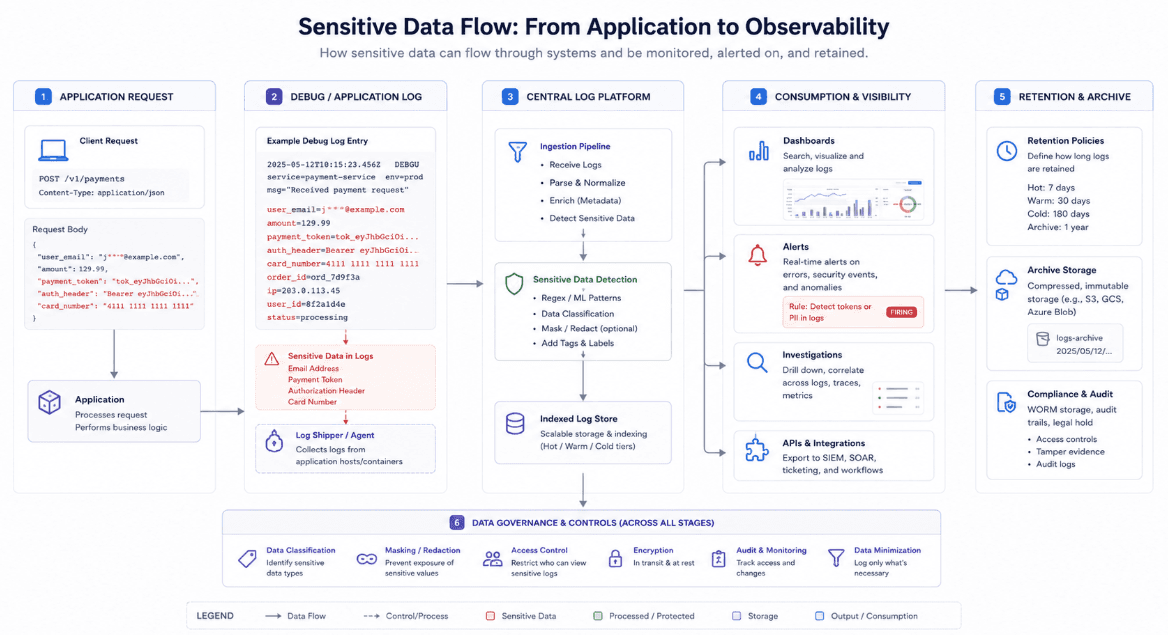
The most common exposure patterns
The first and most obvious pattern is credential leakage. Authorization headers, API keys, session cookies, and bearer tokens sometimes appear in logs through headers, traces, or error messages. Once they are stored, they can be used to impersonate users or services if they remain valid. Even short-lived credentials are dangerous if logs are accessible long enough for an attacker or unauthorized insider to retrieve them.
The second pattern is PII exposure. Email addresses, phone numbers, names, addresses, account numbers, and support identifiers often appear in application logs, especially when debugging onboarding, checkout, or account recovery flows. This creates privacy, compliance, and trust issues because logs are often retained longer and accessed more widely than the original application data.
The third pattern is exception leakage. Stack traces can reveal configuration details, environment names, internal hostnames, file paths, SQL fragments, and serialized request content. While not every stack trace is a secret, enough of them together can create a useful map of the environment. That information can help attackers understand your architecture and look for other weaknesses.
Why observability makes the problem worse
Observability tools are excellent at making information easy to find, and that is exactly why sensitive data is risky there. A log platform is often accessible to more people than the production database, because it is meant to support operations, engineering, support, and incident response. That broader access is reasonable for diagnostics, but dangerous if the logs contain credentials or customer data.
Retention also matters. Many systems store logs for long periods to support forensics, compliance, or trend analysis. That means one accidental leak can survive long after the original code has been fixed. Teams may patch the application, rotate the secret, and assume the issue is gone, while the old value still lives in historical logs, backups, or exports.
Forwarding and integration amplify the blast radius. Logs may be copied into SIEMs, alerting systems, data lakes, or vendor-managed analytics tools. Every additional hop increases the number of places where secrets may persist, and every additional access path increases the chance of accidental exposure.
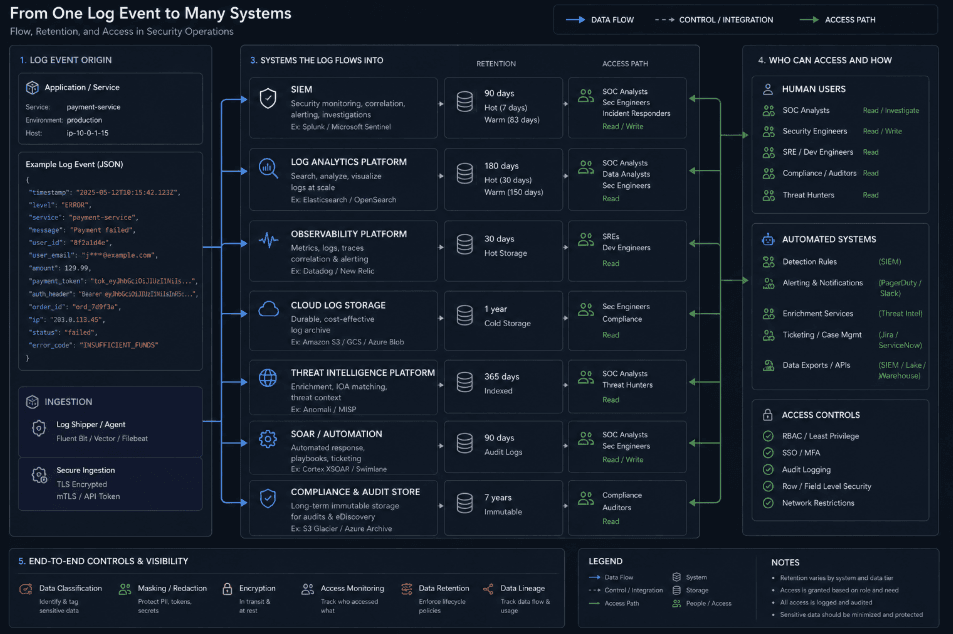
Why this is often missed
Logging leaks are easy to ignore because they are rarely visible in the product itself. A user does not see the issue, a test may pass, and the application continues to function normally. The only sign may be a support case, a security review, or an incident where someone discovers that sensitive values were sitting in plain text inside logs all along.
Teams also tend to assume that redaction happens automatically. In practice, redaction is often partial, inconsistent, or bypassed by custom logging paths. One service may sanitize headers while another logs full bodies. One environment may strip secrets while another debug setting turns them back on. That inconsistency is enough to create exposure even when the team believes a policy already exists.
Another reason the problem persists is that many developers treat logs as operational output rather than data storage. That mindset makes it easy to forget that logs are persistent records with access controls, retention policies, and compliance implications. Once you recognize that, logging starts to look less like a convenience layer and more like another sensitive data system that needs governance.
How to reduce the risk
The most effective control is to log less sensitive data in the first place. Avoid recording authorization headers, session tokens, credentials, full request bodies, and secrets that only exist for authentication or transport. Log event IDs, request IDs, error classes, and safe metadata instead. If a field is not needed to solve an operational problem, it should not be logged.
The next control is structured redaction. Sensitive fields should be masked before logs leave the application boundary, not cleaned later in the pipeline if that can be avoided. Redaction should be consistent across services, frameworks, and environments so that one debug path does not bypass the rest. This is particularly important for APIs and auth flows, where sensitive values can appear in predictable places.
Access control and retention should also be tightened. Not everyone who needs observability access needs raw, unfiltered logs. Limit who can query sensitive streams, restrict exports, and reduce retention where possible. Shorter retention cannot fix a live leak, but it can reduce the damage window and limit the number of places an exposed secret survives.
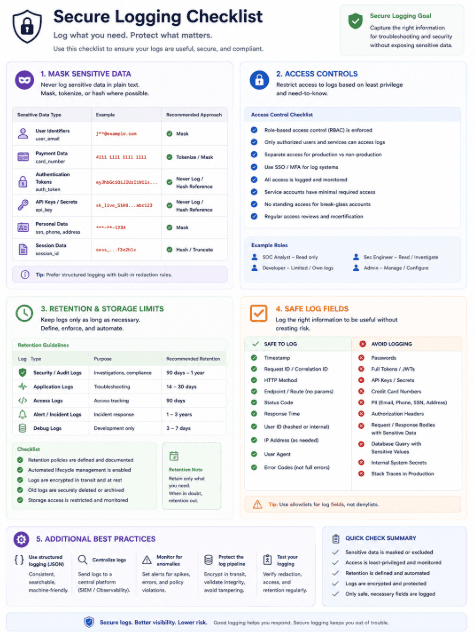
Testing for leaks before attackers find them
Logging should be tested the same way other security-sensitive code paths are tested. Send known secrets through the application in staging and verify that they do not appear in application logs, traces, alert payloads, or downstream storage. Check both success and error paths, because failures are where logging tends to become most verbose.
It is also important to test integrations, not just the application code. Many leaks happen in middleware, proxies, observability agents, or custom alerting rules. If a secret is sanitized in one place but exposed in another, the control is incomplete. Security teams should validate the full path from application event to observability sink.
This is where secret scanning complements application security work. If a tool can detect exposed credentials or sensitive patterns in logs, it helps turn a hidden risk into a measurable one. For teams using Axeploit, that matters because log leakage and secret exposure often travel together: once a secret appears in logs, it can be copied, queried, and reused in ways that create a larger compromise.
The business impact
Log leakage is not just a technical hygiene issue. It can create customer trust problems, privacy concerns, compliance exposure, and incident response overhead. If tokens or credentials are exposed, the team may need to rotate secrets, investigate access, notify stakeholders, and audit historical data. If PII is involved, the impact can be even broader because the organization may need to assess retention, access permissions, and legal obligations.
There is also an operational cost. Logs are supposed to make debugging easier, but a contaminated observability stack can make incident response harder because teams lose confidence in what is safe to query or share. In the worst case, engineers stop trusting logs entirely, which undermines one of the most valuable tools in production operations.
That is why logging needs to be treated as part of the security architecture. It is not enough for logs to be useful. They must also be safe to store, safe to query, and safe to share.
Final perspective
Logging becomes a liability when observability stops being observability and starts becoming a secret repository. The fix is not to stop logging altogether. The fix is to be deliberate about what gets logged, who can access it, how long it is retained, and whether sensitive values are blocked before they ever leave the application.
For DevOps, SRE, and backend teams, that means thinking of logs as production data with security consequences, not just engineering output. The teams that do this well keep the debugging benefits of observability while avoiding one of the most overlooked sources of data exposure in modern systems.



