
There is a recurring pattern in API security discussions that goes something like this: "We have rate limiting, so we're protected against abuse." This statement is roughly as accurate as "We have a lock on the front door, so the building is secure." It is technically a control. It is not, in any meaningful sense, a defense against a motivated adversary.
The problem is not that rate limiting is useless. It handles naive abuse and accidental load well enough. The problem is that the mental model behind most rate limiting implementations , count requests from an identity, block when count exceeds threshold , encodes a set of assumptions about attacker behavior that have been empirically false for at least a decade.
The Mismatch: Volume Thinking vs. Shape Thinking
Defenders think about rate limiting in terms of volume: how many requests per minute, per IP, per account. This is natural because volume is what you measure and what your infrastructure feels. When your API gets 10,000 login attempts from a single IP in an hour, that is obviously abuse, and a simple rate limit catches it.
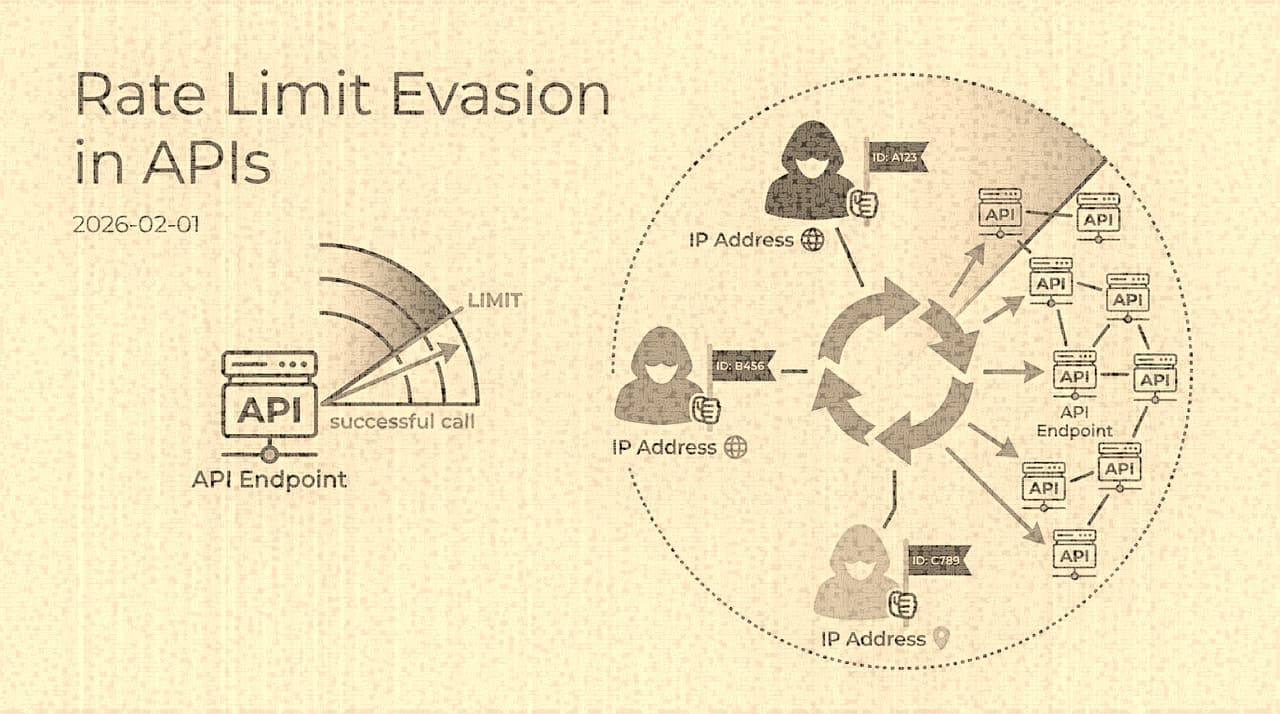
Attackers, meanwhile, think in terms of shape. Their question is not "how many requests can I send?" but "how do I distribute my objective across enough dimensions that no single dimension exceeds its threshold?" The credential stuffing operator who has a list of 10 million username/password pairs does not need to stuff them all from one IP, or through one endpoint, or against one target account, or within one time window. They need to stuff them in aggregate, and the distribution across observable dimensions is a free variable they can optimize.
The residential proxy market made this optimization cheap. Services like those formerly marketed under the Luminati brand (now Bright Data) and dozens of competitors offer access to millions of residential IP addresses at commodity prices , often under $10 per gigabyte of traffic. At the scale of a credential stuffing campaign, where each request is a few hundred bytes, the cost per attempt is fractions of a cent. The attacker can present each request from a distinct residential IP address in the same city as the target user's likely location, with realistic browser fingerprints, at human-plausible intervals.
Against this adversary, a per-IP rate limit of 100 requests per minute is not a defense. It is a specification document for the attacker's distribution strategy.
Credential Stuffing: The Economics That Drive Everything
To understand why rate limit evasion is worth the investment, you have to understand the economics of the credential stuffing industry. Stolen credential lists , sourced from data breaches, infostealer malware, and phishing campaigns , are traded in bulk. The going rate for a fresh, unsorted credential list is low: a few dollars per million entries. Sorted, verified credentials for specific high-value services (banking, e-commerce with stored payment, corporate SSO) command higher prices, but the raw material is cheap.
The attacker's margin comes from the success rate multiplied by the value of a compromised account. If a list of 1 million credentials has a 0.3% success rate against a target service (because users reuse passwords), that yields 3,000 compromised accounts. If each compromised account has an average extractable value of $50 (through stored payment fraud, gift card purchase, or resale of the account itself), the campaign grosses $150,000 from a list that cost perhaps $500 and proxy traffic that cost perhaps $2,000.
At these margins, investing in distribution infrastructure to evade rate limits is rational. The attacker's cost function is approximately:
profit = (list_size * success_rate * account_value) - (list_cost + proxy_cost + tooling_cost)
Rate limiting only matters to the extent it reduces the effective list_size , i.e., how many credentials the attacker can actually attempt before being blocked. If your rate limits allow them to work through the entire list (just more slowly, or across more IPs), you have not reduced their profit. You have imposed a time delay they can absorb.
The Dimension Evasion Playbook
Real abuse campaigns combine multiple evasion tactics simultaneously. The goal is not to defeat any single control but to ensure that no single observable dimension crosses its threshold:
The important insight here is that evasion is not about any single clever trick. It is about the combinatorial cost of detection. If you monitor five dimensions independently, the attacker needs to stay below threshold on each one. If you monitor five dimensions independently and correlate across them, the attacker must distribute across the product of those dimensions, which is materially harder and more expensive.
Why Common Rate Limiting Architectures Fail
Most rate limiting implementations share a structural weakness: they enforce limits at the point where requests arrive, not at the point where abuse intent accumulates. Consider the standard patterns:
Per-IP limits defend against a single-origin flood. They are irrelevant against distributed campaigns using residential proxies. Worse, they cause false positives for legitimate users behind corporate NATs, shared WiFi, or carrier-grade NAT, where thousands of real users share a single egress IP.
Per-account limits defend against brute-forcing a single account. They do not detect credential stuffing, where the attacker attempts one password per account across millions of accounts. Each account sees exactly one attempt , well below any reasonable threshold.
Per-route limits defend against endpoint-specific abuse. They miss attacks that spread across functionally equivalent endpoints (login via web, mobile API, GraphQL mutation, SSO callback) or that combine reconnaissance on one endpoint with exploitation on another.
Global limits defend against total load. They are useless for targeted abuse at volumes well below the global capacity, and they punish all users equally for one attacker's behavior.
The common theme: each limiter looks at one slice of reality. The attacker operates across slices.
Toward Intent-Based Abuse Detection
The alternative to threshold counting is modeling attacker intent. Instead of asking "has this IP sent too many requests?" you ask "does the aggregate behavior across this set of IPs, accounts, and endpoints look like a credential stuffing campaign?"
This is harder to implement but qualitatively different in what it catches. Some concrete approaches:
Multi-dimensional quota correlation. Apply budgets simultaneously across IP, ASN, account, device fingerprint, and route group. When an entity is near-threshold on multiple dimensions simultaneously, escalate. An IP sending 90% of its per-IP limit while also being associated with a device fingerprint at 85% of its limit and hitting a route group at 80% of its limit is far more suspicious than any single dimension at 100%.
Behavioral velocity scoring. Instead of counting raw requests, count the rate of distinct credential pairs attempted. A legitimate user may retry their own password several times (generating multiple requests to the same account), but they will not attempt credentials for 500 different accounts. A credential stuffing bot, conversely, will attempt many distinct accounts at a low per-account rate. The velocity of unique account targets is a stronger signal than the velocity of raw requests.
Session coherence analysis. Real users have browsing patterns that precede login attempts , they visit the homepage, navigate to the login page, possibly interact with a CAPTCHA or cookie consent dialog. Automated stuffing tools often skip straight to the login endpoint, or exhibit session patterns that are internally consistent (same timing, same header ordering, same TLS fingerprint across thousands of "different users") in ways that real browser diversity does not produce.
Economic friction ladders. Rather than binary blocking (which tells the attacker exactly when they have been detected and prompts them to adapt), apply graduated friction that increases the cost of each successive attempt:
Stage 1: Transparent delay (add 200-500ms latency)
Stage 2: Proof-of-work challenge (client must compute before submitting)
Stage 3: Interactive challenge (CAPTCHA or device verification)
Stage 4: Step-up authentication requirement
Stage 5: Temporary lockout with analyst review
The key insight is that each stage increases the attacker's cost per attempt without providing a clear signal of where the detection boundary lies. The attacker's ROI degrades gradually rather than hitting a cliff they can map and avoid.
A Policy Schema That Reflects This Thinking
The configuration for an intent-aware system looks qualitatively different from a simple rate limit rule. Instead of { "ip": "100/min" }, you express multi-dimensional policy:
{
"policy": "credential-abuse-detection",
"observation_window_minutes": 60,
"dimensions": {
"ip": { "soft_limit": 50, "hard_limit": 200 },
"asn": { "soft_limit": 500, "hard_limit": 2000 },
"device_fingerprint": { "soft_limit": 30, "hard_limit": 100 },
"target_account_velocity": { "unique_accounts_per_hour": 20 },
"route_group": { "group": "authentication", "soft_limit": 40 }
},
"correlation_rules": [
{
"condition": "any 3 dimensions above 70% of soft_limit simultaneously",
"action": "escalate_to_stage_2"
},
{
"condition": "target_account_velocity exceeded",
"action": "escalate_to_stage_3"
}
],
"friction_ladder": ["delay", "pow_challenge", "captcha", "step_up_auth", "block_and_review"]
}This is more complex to operate than a flat rate limit. It requires more telemetry, more state, and more tuning. But it models the actual threat , distributed, multi-dimensional, intent-driven abuse , rather than the simplified threat that rate limits were designed for.
The Honest Assessment
None of this is a complete solution. Sufficiently sophisticated attackers will adapt to intent-based detection just as they adapted to threshold-based rate limiting. The game is adversarial, and the defender's advantage is not in building an unbreakable wall but in raising the attacker's cost per successful attempt until the economics of the campaign no longer favor the attacker.
If your rate limit costs the attacker nothing to circumvent (because they can trivially distribute below your thresholds), you have no defense. If your detection system raises the cost per attempt by 10x (through challenges, delays, and adaptive blocking), you have shifted the breakeven point. At some cost level, the attacker's campaign becomes unprofitable against your service and they move to an easier target.
This is the unsexy truth about API abuse defense: it is an economic competition, not a technical one. The question is not "can we stop all abuse?" but "can we make abuse against our service more expensive than abuse against our competitors?" The answer depends less on your rate limiting algorithm and more on how many dimensions of attacker behavior you can observe, correlate, and impose friction against.
Rate limiting measures volume. Abuse detection measures intent. If your controls only see the former, attackers will simply optimize for the latter.